I'm a big fan of Rad's Telemetry profiler, which I used at Valve for various Linux profiling tasks, but it's unfortunately out of reach to independent developers. So I'm just making my own mini version of Telemetry, using imgui for the UI. For most uses Telemetry itself is actually overkill anyway. I may open source this if I can find the time to polish it more.
I've optimized LZHAM v1.1's compressor for more efficient multithreading vs. v1.0, but it's still doesn't scale quite as much as I was hoping. Average utilization on Core i7 Gulftown (6 cores) is only around 50-75%. Previously, the main thread would wait for all parsing jobs to complete before coding, v1.1 can now overlap parsing and coding. I also optimized the match finder so it initializes more quickly at the beginning of each block, and the finder jobs are a little faster.
Here are the results on LZHAM v1.1 (currently on github here), limited to 6 total threads, after a few hours of messing around learning imgui. Not all the time in compress_block_internal() has been marked up for profiling, but it's a start:
![]()
Thread 0 is the main thread, while threads 1-5 are controlled by the task pool. The flow of time is from left to right, and this view visualizes approx. 616.4ms.
At the beginning of a block, the compressor allocated 5 total threads for match finding and 2 total threads for parsing.
The major operations:
- Thread 0 (the caller's thread) controls everything. compress_block_internal() is where each 512KB block is compressed. find_all_matches() prepares the data structures used by the parallel match finder, kicks off a bunch of find_matches_mt() tasks to find matches for the entire block, then it finds all the nearest len2 matches for the entire block. After this is done it begins parsing (which can be done in parallel) and coding (which must be done serially).
The main thread proceeds to process the 512KB input block in groups of (typically) 3KB "parse chunks". Several 3KB chunks can be parsed in parallel within a single group, but all work within a group must finish before proceeding to the next group.
- Coding is always done by thread 0.
Thread 0 waits for each chunk in a group to be parsed before it codes the results. Coding must proceed sequentially, which is why it's on thread 0. The first chunk in a group is always parsed on thread 0, while the other chunks in the group may be parsed using jobs on the thread pool. The parse group size is dynamically increased as the match finders finish up in order to keep the thread pool's utilization high.
- Threads 1-5 are controlled by the thread pool. In LZHAM v1.1, there are only two task types: match finding, and parsing. The parsers consume the match finder's output, and the main thread consumes the parser's output. Coding is downstream of everything.
The match finders may sometimes spin and then sleep if they get too far ahead of the finders, which happens more than I would like (match finding is usually the bottleneck). This can cause the main thread to stall as it tries to code each chunk in a group.
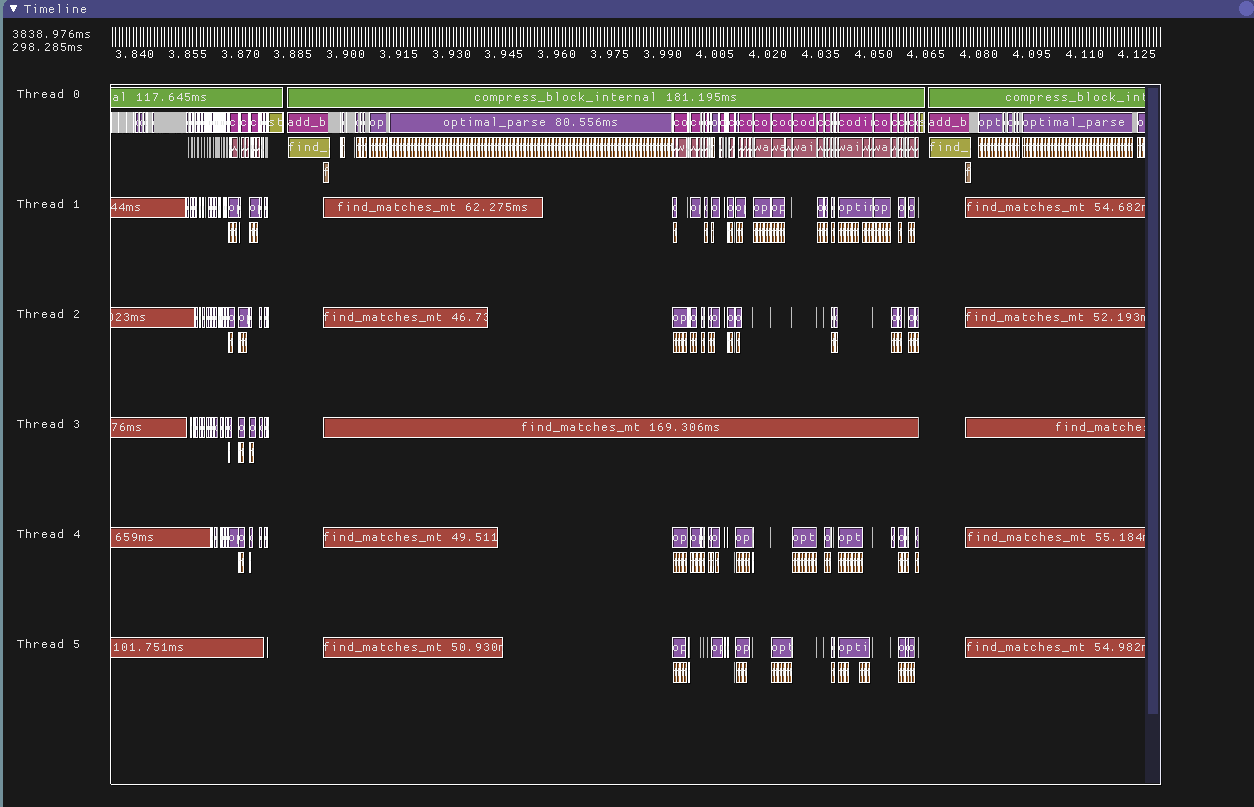
Here's a zoom in of the above graph, showing the parsers having to wait in various places:
![]()
Some of the issues I can see with LZHAM v1.1's multithreading:
- find_all_matches() is single threaded, and the world stops until this function finishes, limiting parallelization.
- find_len2_matches() should be a task.
- It's not visualized here, but the adler32() call (done once per block) can also be a task. Currently, it's done once on thread 0 after the finder tasks are kicked off.
- The finder tasks should take roughly the same amount of time to execute, but it's clear that the finder job on thread 4 took much longer than the others.
Here's an example of a very unbalanced situation on thread 3. These long finder tasks need to be split up into much smaller tasks.
![]()
- There's some serial work in stop_encoding(), which takes around 5ms. This function interleaves the arithmetic and Huffman codes into a single output bitstream.
v1.1 is basically ready, I just need to push it to the main github repo. I'm going to refine the profiler and then use it to tune LZHAM v1.1's multithreading more.
I've optimized LZHAM v1.1's compressor for more efficient multithreading vs. v1.0, but it's still doesn't scale quite as much as I was hoping. Average utilization on Core i7 Gulftown (6 cores) is only around 50-75%. Previously, the main thread would wait for all parsing jobs to complete before coding, v1.1 can now overlap parsing and coding. I also optimized the match finder so it initializes more quickly at the beginning of each block, and the finder jobs are a little faster.
Here are the results on LZHAM v1.1 (currently on github here), limited to 6 total threads, after a few hours of messing around learning imgui. Not all the time in compress_block_internal() has been marked up for profiling, but it's a start:
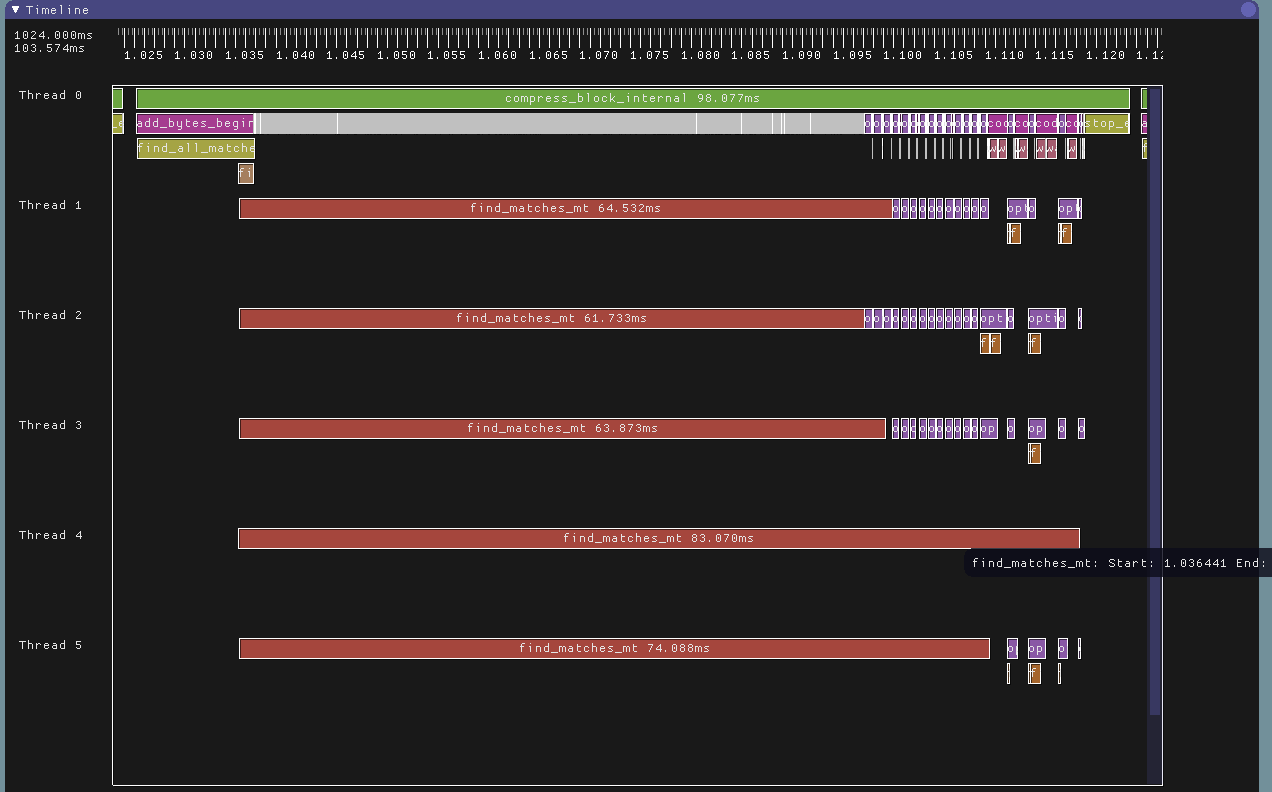
Thread 0 is the main thread, while threads 1-5 are controlled by the task pool. The flow of time is from left to right, and this view visualizes approx. 616.4ms.
At the beginning of a block, the compressor allocated 5 total threads for match finding and 2 total threads for parsing.
The major operations:
- Thread 0 (the caller's thread) controls everything. compress_block_internal() is where each 512KB block is compressed. find_all_matches() prepares the data structures used by the parallel match finder, kicks off a bunch of find_matches_mt() tasks to find matches for the entire block, then it finds all the nearest len2 matches for the entire block. After this is done it begins parsing (which can be done in parallel) and coding (which must be done serially).
The main thread proceeds to process the 512KB input block in groups of (typically) 3KB "parse chunks". Several 3KB chunks can be parsed in parallel within a single group, but all work within a group must finish before proceeding to the next group.
- Coding is always done by thread 0.
Thread 0 waits for each chunk in a group to be parsed before it codes the results. Coding must proceed sequentially, which is why it's on thread 0. The first chunk in a group is always parsed on thread 0, while the other chunks in the group may be parsed using jobs on the thread pool. The parse group size is dynamically increased as the match finders finish up in order to keep the thread pool's utilization high.
- Threads 1-5 are controlled by the thread pool. In LZHAM v1.1, there are only two task types: match finding, and parsing. The parsers consume the match finder's output, and the main thread consumes the parser's output. Coding is downstream of everything.
The match finders may sometimes spin and then sleep if they get too far ahead of the finders, which happens more than I would like (match finding is usually the bottleneck). This can cause the main thread to stall as it tries to code each chunk in a group.
Here's a zoom in of the above graph, showing the parsers having to wait in various places:

Some of the issues I can see with LZHAM v1.1's multithreading:
- find_all_matches() is single threaded, and the world stops until this function finishes, limiting parallelization.
- find_len2_matches() should be a task.
- It's not visualized here, but the adler32() call (done once per block) can also be a task. Currently, it's done once on thread 0 after the finder tasks are kicked off.
- The finder tasks should take roughly the same amount of time to execute, but it's clear that the finder job on thread 4 took much longer than the others.
Here's an example of a very unbalanced situation on thread 3. These long finder tasks need to be split up into much smaller tasks.
- There's some serial work in stop_encoding(), which takes around 5ms. This function interleaves the arithmetic and Huffman codes into a single output bitstream.
v1.1 is basically ready, I just need to push it to the main github repo. I'm going to refine the profiler and then use it to tune LZHAM v1.1's multithreading more.















