Intro
I’m now starting to deeply analyze the performance of two new general purpose data compression codecs. One is Google’s Brotli codec, another is a brand new codec from Rad Game Tools named “BitKnit”. Both codecs are attempting to displace zlib, which is used by the Linux kernel, and is one of the most used compression libraries in the world. So I’m paying very close attention to what’s going on here.
To put things into perspective, in the lossless compression world we’re lucky to see a significant advancement every 5-10 years. Now, we have two independently implemented codecs that are giving zlib serious competition on multiple axes: throughput, ratio, and even code size.
Summary
I’m now using what I think is a very interesting and insightful approach to deeply analyze the practical performance characteristics of lossless codecs. As I learned while working on the Steam Linux/SteamOS project, robust benchmarking can be extremely difficult in practice. So I'm still gathering and analyzing the data, and tweaking how it’s graphed. What I’ve seen so far looks very interesting for multiple reasons.
First, it's looking pretty certain that both BitKnit and Brotli compete extremely well against zlib's decompression performance, but at much higher (LZMA/LZHAM-like) compression ratios. Amazingly, BitKnit’s compressor is also extremely fast, around the same speed as zlib’s. (By comparison, at maximum compression levels, both Brotli’s and LZHAM's compressors are pretty slow.) The graphs in this post only focus on decompression throughput, however. I’m saving the compression throughput analysis for another post.
One rough way of judging the complexity of a compressor vs. others is to compare the number of lines of code in each implementation. BitKnit at 2,700 lines of code (including comments) is smaller than both LZ4 (3,306 - no comments), zlib's (23,845 - no comments, incl. 3k lines of asm), or LZHAM’s (11,651 - no comments). Brotli's is rather large at 47,919 lines (no comments), but some fraction of this consists of embedded static tables.
Interestingly to me, BitKnit’s decompressor uses around half the temporary work RAM of LZHAM's (16k vs. 34k).
New Benchmarking Approach
While writing and analyzing LZHAM I started with a tiny set (like 5-10) of files for early testing. I spent a huge amount of time optimizing the compressor to excel on large text XML files such as enwik8/9, which are popular in the lossless data compression world. I consider this a serious mistake, so I've been rethinking how to best benchmark these systems.
The new codec analysis approach I’m using runs each decompressor on thousands of test corpus files, then I plot the resulting (throughput, ratio) data pairs in Excel using scatter graphs. The data points are colored by codec, and the points are transparent so regions with higher density (or with data points from multiple overlapping codecs) are more easily visualized. This is far better than what the Squash Compression Benchmark does IMO, because at a single glance you can see the results on thousands of (hopefully interesting) files, instead of the results on only a single file at a time from a tiny set of corpus files.
I generated these scatter graphs on 12k data files from the final LZHAM vs. LZMA corpus. There is some value in using these data files, because I used this same test corpus to analyze LZHAM to ensure it was competitive against LZMA. This corpus consists of a mix of game data, traditional textual data, every other compression corpus I could get my hands on, some artificial XML/JSON/UBJ test data, and lots of other interesting stuff I’ve encountered on the various projects I’ve worked on over the years. (Unfortunately, I cannot publicly distribute the bulk of these data files until someone comes up with an approach that allows me to share the corpus in a one way encrypted manner that doesn’t significantly impact throughput or ratio. I have no idea how this could really be done, or even if it's possible.)
The Data
The X axis is decompression throughput (right=faster), and the Y axis is compression ratio (higher=better ratio or more compression). The very bottom of the graph is the uncompressible line (ratio=1.0).
Color code:
Black/Gray = LZHAM
Red = Brotli
Green = zlib
Blue = BitKnit
Yellow = LZ4
Totals for 11,999 files (including uncompressible files):
Uncomp: 2,499,169,096
lz4: 1,167,777,908 2.14
zlib: 1,044,180,362 2.39
brotli: 918,949,263 2.72
bitknit: 898,621,908 2.78
lzham: 882,723,287 2.83
Totals after removing 1,330 files with a zlib compression ratio less than 1.1 (i.e. uncompressible files):
Totals after removing 1,330 files with a zlib compression ratio less than 1.1 (i.e. uncompressible files):
Uncomp: 2,147,530,394
lz4: 815,221,536 2.63
zlib: 693,090,474 3.1
brotli: 568,461,065 3.78
bitknit: 547,869,148 3.92
lzham: 532,235,143 4.03
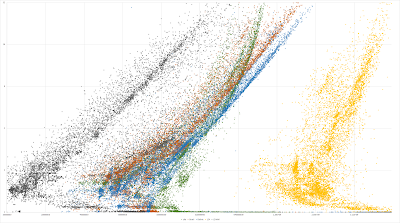
This is a log2 log2 plot, basically an overview of the data:
![]()
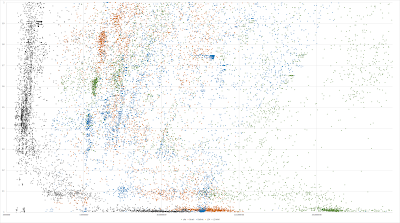
This is a zoomed linear plot , looking more closely at the uncompressible (ratio=1) or nearly uncompressible (ratio very close but not 1) regions:
![]()
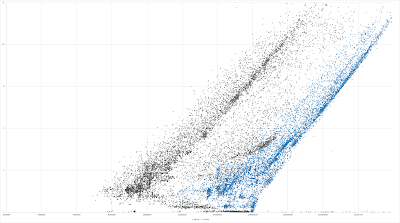
This log2 log2 plot is limited to just LZHAM vs. BitKnit:
![]()
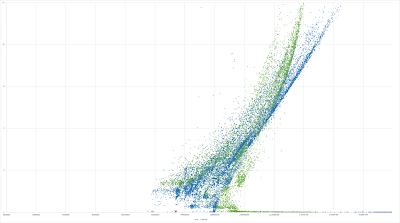
![]()
Fabian Giesen (Rad) and I have noticed several interesting things about these scatter plots:
- The data points with a ratio of 1 (or extremely close to 1) show how well the algorithm handles uncompressible data, which is hopefully near memcpy() performance.
(Note LZMA’s data will be very interesting, because it doesn’t have good handling for uncompressible data.)
There are a handful (around 50-60 depending on the codec) of data points with a ratio slightly below 1 (.963-.999). The majority are small (287-1kb) uncompressible files.
- Slightly "above" this ratio (very close to ratio 1, but not quite), literal handling dominates the decompressor's workload. There are distinct clusters on and near the ratio=1 line for each compressor.
LZHAM actually does kinda well here vs. the others, but it falls apart rapidly as the ratio increases.
- Notice the rough pushed down "<" shape of each algorithm's plot. LZHAM's is pretty noticeable. At the bottom right (ratios at/close to 1.0), literals dominate the decompression time.
Interpreting this as if all algorithms are plain LZ with discrete literals and matches:
As you go "up" to higher ratios, the decompressor has to process more and more matches, which (at least in LZHAM) are more expensive to handle vs. literals. After the “bend”, as you go up and to the right the matches grow increasingly numerous and longer (on average).
- LZHAM has an odd little cluster of data points to the right (on the ratio ~3 line) where it almost keeps up with BitKnit. Wonder what that is exactly? (Perhaps lots of easily decoded rep matches?)
- All test corpus files are between 256 bytes and 127.7 MB
- All algorithms were directly linked into the executable, and the decompressors were invoked in the same way
- Each decompressor is invoked repeatedly in a loop until 10ms has elapsed, this is done 4 times and shortest average runtime is taken
- Brotli was limited to comp level 9, as level 10 can be too slow for rapid experimentation, 16MB dictionary size (the largest it supports)
- LZHAM was limited to using its regular parser (not it's best of X arrivals parser, i.e. the "extreme parsing" flag was disabled), 64MB dictionary size.
- LZ4HC compressor, level 8
- zlib's asm modules were not used in this run. It'll be interesting to see what difference the asm optimizations make.
This is a zoomed linear plot , looking more closely at the uncompressible (ratio=1) or nearly uncompressible (ratio very close but not 1) regions:
This log2 log2 plot is limited to just LZHAM vs. BitKnit:
Finally, another log2 log2 plot showing just BitKnit vs. zlib:
Current Observations
Fabian Giesen (Rad) and I have noticed several interesting things about these scatter plots:
- The data points with a ratio of 1 (or extremely close to 1) show how well the algorithm handles uncompressible data, which is hopefully near memcpy() performance.
(Note LZMA’s data will be very interesting, because it doesn’t have good handling for uncompressible data.)
There are a handful (around 50-60 depending on the codec) of data points with a ratio slightly below 1 (.963-.999). The majority are small (287-1kb) uncompressible files.
- Slightly "above" this ratio (very close to ratio 1, but not quite), literal handling dominates the decompressor's workload. There are distinct clusters on and near the ratio=1 line for each compressor.
LZHAM actually does kinda well here vs. the others, but it falls apart rapidly as the ratio increases.
- Notice the rough pushed down "<" shape of each algorithm's plot. LZHAM's is pretty noticeable. At the bottom right (ratios at/close to 1.0), literals dominate the decompression time.
Interpreting this as if all algorithms are plain LZ with discrete literals and matches:
As you go "up" to higher ratios, the decompressor has to process more and more matches, which (at least in LZHAM) are more expensive to handle vs. literals. After the “bend”, as you go up and to the right the matches grow increasingly numerous and longer (on average).
- LZHAM has an odd little cluster of data points to the right (on the ratio ~3 line) where it almost keeps up with BitKnit. Wonder what that is exactly? (Perhaps lots of easily decoded rep matches?)
- Notice zlib’s throughput stops increasing and plateaus as the ratio increases - why is that? Somebody needs to dive into zlib’s decompressor and see why it’s not scaling here.
I need to add my implementation of zlib’s core API (miniz) to see how well it compares.
Important Notes:
- The x64 benchmark command line app was run on Win10, 2x Xeon E5-2690 V2 3.0GHz (20 cores/40 threads). Benchmark app is single threaded.
I need to add my implementation of zlib’s core API (miniz) to see how well it compares.
Important Notes:
- The x64 benchmark command line app was run on Win10, 2x Xeon E5-2690 V2 3.0GHz (20 cores/40 threads). Benchmark app is single threaded.
- All test corpus files are between 256 bytes and 127.7 MB
- All algorithms were directly linked into the executable, and the decompressors were invoked in the same way
- Each decompressor is invoked repeatedly in a loop until 10ms has elapsed, this is done 4 times and shortest average runtime is taken
- Brotli was limited to comp level 9, as level 10 can be too slow for rapid experimentation, 16MB dictionary size (the largest it supports)
- LZHAM was limited to using its regular parser (not it's best of X arrivals parser, i.e. the "extreme parsing" flag was disabled), 64MB dictionary size.
- LZ4HC compressor, level 8
- zlib's asm modules were not used in this run. It'll be interesting to see what difference the asm optimizations make.
Next Step
The next major update will also show LZMA, Zstd, and miniz. I'm also going to throw some classes from crunch in here to clusterize the samples, so we can get a better idea of how well each algorithm performs on different classes of data.
I feel strongly that scatter graphs like these can be used to help intelligently guide the design and implementation of new practical compressors.
I feel strongly that scatter graphs like these can be used to help intelligently guide the design and implementation of new practical compressors.
A big thanks to Fabian “ryg” Giesen at Rad Game Tools for giving me access to "BitKnit" for analysis. BitKnit is going to be released in the next major version of Oodle, Rad’s network and general purpose data compression product.