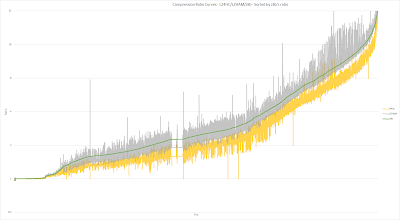
Continuing yesterday's post, here are the compression ratios for all 12k data points (between 256 -128MB) in the LZHAM vs. LZMA test file corpus, on various codecs: LZ4HC L8, Brotli L9, Rad's BitKnit VeryHigh, LZHAM m4, and of course zlib L9.
Vertical Axis = Compression ratio (higher is more compression)
Horizontal Axis = File, sorted purely by zlib's compression ratio
Color = Codec (using the same color coding as my previous post)
The data points have been sorted by zlib's compression ratio, which is why the green line is so nice and smooth. These are the same data points as yesterday's scatter graphs.
LZ4HC vs. BitKnit vs. zlib:

LZ4HC vs. Brotli vs. zlib:

Brotli vs. BitKnit vs. zlib:

Here are a couple bonus plots, this time for LZHAM vs. LZ4HC or Brotli:

Comments:
It's clear from looking at these plots that simply stating "codec X has a higher ratio than codec Y" is at best a gross approximation. It highly depends on the file's content, the file's size, and even how well a file's content resembles what the codec designer's tuned the codec to handle best.
For example, Brotli has special optimizations (such as a precomputed static dictionary) for textual data. Also, like zlib, it uses entropy coding tables (the Huffman symbol code lengths) precomputed by the compressor, which can give it the edge on smaller files vs. codecs that use purely adaptive table updating approaches like LZHAM. (Also, I would imagine that the more stationary the data source, the more precomputed Huffman tables make sense.)
Another advantage Brotli shares with zlib due to its usage of precomputed Huffman tables: It doesn't need to spend valuable CPU time computing Huffman code lengths during decompression. LZHAM struggles to do this quickly, particularly on small files (less than approx. 4-8KB) where most decompression time is spent computing Huffman code lengths (and not actually decompressing the file!).
It's also possible to design a codec to be very strong at handling binary files. Apparently, BitKnit is tuned more in this direction. It still handles text files well, but it makes some intelligent design tradeoffs that favor really high and symmetrical compression/decompression performance with only a small sacrifice to text file ratios. This tradeoff makes a lot of sense, particularly in the game development context where a lot of data files are in various special binary formats.
Interestingly, Brotli and BitKnit seem to flip flop back and forth as to who is best ratio-wise. There are noticeable clusters of files where Brotli is slightly better, then clusters with BitKnit. I'll be analyzing these clusters soon to attempt to see what's going on. I believe this helps show that this data file corpus has a decent amount of interesting variety.
Finally, Brotli's compression ratio is just about always at least as good as zlib's (or extremely close). IMO, the Brotli team's Zopfli roots are showing strongly here.
Next Steps:
Looking into the future, it may be a good idea for the next major compressor to support both precomputed (Brotli-style) and semi-adaptive (LZHAM and presumably BitKnit-style) entropy table updating approaches.
Thanks to Blue Shift's CEO, John Brooks, for suggesting to chart this way.