This is basically a quick research report, summarizing what we currently know about binary delta compression. If you have any feedback or ideas, please let us know.
Binary delta compression (or
here) is very important now. So important that I will not be writing a new compressor that doesn't support the concept in some way. When I first started at Unity, Joachim Ante (CTO) and I had several long conversations about this topic. One application is to use delta compression to patch an "old" Unity
asset bundle (basically an archive of objects such as textures, animations, meshes, sounds, metadata, etc.), perhaps made with an earlier version of Unity, to a new asset bundle file that can contain new objects, modified objects, deleted objects, and even be in a completely different asset bundle format.
Okay, but why is this useful?
One reason asset bundle patching via delta compression is important to Unity developers is because some are still using an old version of Unity (such as v4.6), because their end users have downloadable content stored in asset bundle files that are not directly compatible with newer Unity versions. One brute force solution for Unity devs is to just upgrade to Unity 5.x and re-send all the asset bundles to their end users, and move on until the next time this happens. Mobile download limits, and end user's time, are two important constraints here.
Basically, game makers can't expect their customers to re-download all new asset bundles every time Unity is significantly upgraded. Unity needs the freedom to change the asset bundle format without significantly impacting developer's ability to upgrade live games. Binary delta compression is one solution.
Another reason delta compression is important, unrelated to Unity versioning issues: it could allow Unity developers to efficiently upgrade a live game's asset bundles, without requiring end users to redownload them in their entirety.
There are possibly other useful applications we're thinking about, related to
Unity Cloud Build.
Let's build a prototype
First, before building anything new in a complex field like this you should
study what others have done. There's been some work in this area, but surprisingly not a whole lot. It's a somewhat niche subject that has focused way too much on patching executable files.
During our discussions, I mentioned that
LZHAM already supports a delta compression mode. But this mode is only workable if you've got plenty of RAM to store the entire old and new files at once. That's definitely not gonna fly on mobile, whatever solution we adopt must use around 5-10MB of RAM.
bsdiff seems to be the best we've got right now in the open source space. (If you know of something better, please let us know!) I've been
looking and probing at the code. Unfortunately bsdiff does not scale to large files either because it requires all file data to be in memory at once, so we can't afford to use it as-is on mobile platforms. Critically, bsdiff also crashes on some input pairs, and it slows down massively on some inputs. It's a start but it needs work.
Some Terminology
"Unity dev" = local game developer with all data ("old" and "new")
"End user" = remote user (and the Unity dev's customer), we must transmit something to change their "old" data to "new" data
Old file - The original data, which both sides (Unity dev and the end user) already have
New file - The new data the Unity dev wants to send to the end user
Patch file - The compressed "patch control stream" that Unity dev transmits to end users
Delta compressor inputs: Old file, New file
Delta compressor outputs: Patch file
Delta decompressor inputs: Old file, Patch file
Delta decompressor outputs: New file
The whole point of this process is that it can be vastly cheaper to send a compressed patch file than a compressed new file.
The old and new files are asset bundle files in our use case.
Bring in deltacomp
"deltacomp" is our memory efficient patching prototype that leverages
minibsdiff, which is basically bsdiff in library form. We now have a usable beachhead we understand in this space, to better learn about the real problems. This is surely not the optimal approach, but it's something.
Most importantly, deltacomp divides up the problem into small (1-2MB) mobile-friendly blocks in a way that doesn't wreck your compression ratio. The problem of how to decide which "old" file blocks best match "new" file blocks involves computing what we're calling a file "cross correlation" matrix (CCM), which I blogged about
here and
here.
We now know that computing the CCM can be done using brute force (insanely slow, even on little ~5MB files), an rsync-style rolling hash (Fabian at Rad's idea), or using a simple probabilistic sampling technique (our current approach). Thankfully the problem is also easily parallelizable, but that can't be your only solution (because not every Unity customer has a 20 core workstation).
deltacomp's compressor conceptually works like this:
1. User provides old and new files, either in memory or on disk.
2. Compute the CCM. Old blocks use a larger block size of 2*X (starting every X bytes, so they overlap), new blocks use a block size of X (to accommodate the expansion or shifting around of data).
A CCM on an executable file (Unity46.exe) looks like this:
![]()
In current testing, the block size can be from .5MB to 2MB. (Larger than this requires too much temporary RAM during decompression. Smaller than this could require too much file seeking within the old file.)
3. Now for each new block we need a list of candidate old blocks which match it well. We find these old blocks by scanning through a column in the CCM matrix to find the top X candidate block pairs.
We can either find 1 candidate, or X candidates, etc.
4. Now for each candidate pair, preprocess the old/new block data using minidiff, then pack this data using LZHAM. Find the candidate pair that gives you the best ratio, and remember how many bytes it compressed to.
5. Now just pack the new block (by itself - not patching) using LZHAM. Remember how many bytes it compressed to.
6. Now we need to decide how to store this new file block in the patch file's compressed data stream. The block modes are:
- Raw
- Clone
- Patch (delta compress)
So in this step we either output the new file data as-is (raw), not store it at all (clone from the old file), or we apply the minibsdiff patch preprocess to the old/new data and output that.
The decision on which mode to use depends on the trial LZHAM compressions stages done in steps 4 and 5.
7. Finally, we now have an array of structs describing how each new block is compressed, along with a big blob of data to compress from step 6 with something like LZMA/LZHAM. Output a header, the control structs, and the compressed data to the patch file. (Optionally, compress the structs too.)
We use a small sliding dictionary size, like ~4MB, otherwise the memory footprint for mobile decompression is too large.
This is the basic approach. Alexander Suvorov at Unity found a few improvements:
1. Allow a new block to be delta compressed against a previously sent new block.
2. The order of new blocks is a degree of freedom, so try different orderings to see if they improve compression.
3. This algorithm ignores the cost of seeking on the old file. If the cost is significant, you can favor old file blocks closest to the ones you've already used in step 3.
Decompression is easy, fast, and low memory. Just iterate through each new file block, decompress that block's data (if any - it could be a cloned block) using streaming decompression, optionally unpatch the decompressed data, and write the new data to disk.
Current Results
Properly validating and quantifying the performance of a new codec is tough. Testing a delta compressor is tougher because it's not always easy to find relevant data pairs. We're working with several game developers to get their data for proper evaluation. Here's what we've got right now:
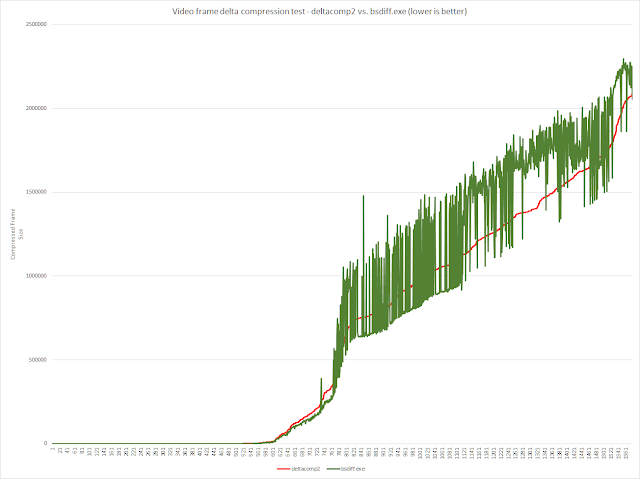
- FRAPS video frames - Portal 2
1578 frames, 1680x1050, 3 bytes per pixel .TGA, each file = 5292044 bytes
Each frame's .TGA is delta compressed against the previous frame.
Total size: 8,350,845,432
deltacomp2: 1,025,866,924
bsdiff.exe: 1,140,350,969
deltacomp2 has a ~10% better avg ratio vs. bsdiff.exe on this data.
Compressed size of individual frames:
Compressed size of individual frames, sorted by delta2comp frame size:- FRAPS video frames - Dota2:
1807 frames, 2560x1440, 3 bytes per pixel .TGA, each file = 11059244 bytes
Each frame's .TGA is delta compressed against the previous frame.
Total size: 19,984,053,908
deltacomp2: 6,806,289,758
bsdiff.exe: 7,082,896,772
deltacomp2 has a ~3.9% better avg ratio vs. bsdiff.exe on this data.
Compressed size of individual frames:
Above, the bsdiff sample near 1303 falls to 0 because it crashed on that data pair. bsdiff itself is unreliable, thankfully minibsdiff isn't crashing (but it still has perf. problems).
Compressed size of individual frames, sorted by delta2comp frame size:- Firefox v10-v39 installer data
Test procedure: Unzip each installer archive to separate directory, iterate through all extracted files, sort files by filename and path. Now delta compress each file against its predecessor, i.e. "dict.txt" from v10 is the "old" file for "dict.txt" in v11, etc.
Total file pairs: 946
Total "old" file size: 1,549,458,206
Total "new" file size: 1,570,672,544
deltacomp2 total compressed size: 563,130,644
bsdiff.exe total compressed size: 586,356,328
Overall deltacomp2 was 4% better than bsdiff.exe on this data.
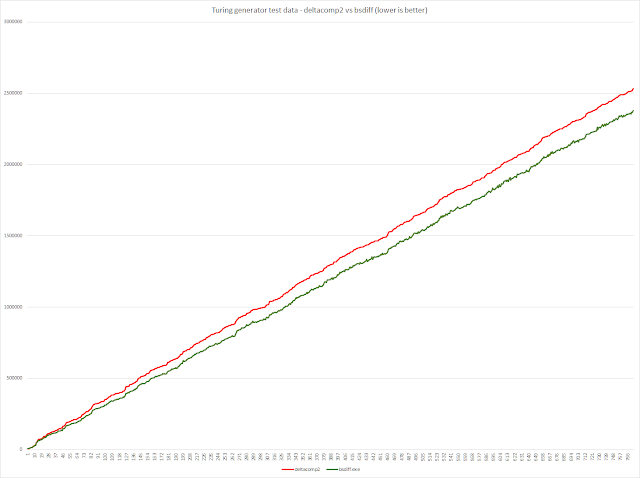
- UIQ2 Turing generator data
Test consists of delta compressing pairs of very similar, artificially generated test data.
773 file pairs
Total "old" file size: 7,613,150,654
Total "new" file size: 7,613,181,130
Total deltacomp2 compressed file size: 994,100,836
Total bsdiff.exe compressed file size: 920,170,669
Interestingly, deltacomp2's output is ~8% larger than bsdiff.exe's on this artificial test data.
I'll post more data soon, once we get our hands on real game data that changes over time.
Next Steps
The next mini-step is to have another team member try and break the current prototype. We already know that minibsdiff's performance isn't stable enough. On some inputs it can get very slow. We need to either fix this or just rewrite it. We've already switched to libdivsufsort to speed up the suffix array sort.
The next major step is to dig deeply into Unity's asset bundle and virtual file system code and build a proper asset bundle patching tool.
Finally, on the algorithm axis, another different approach is to just ditch the preprocessing idea using minibsdiff and implement
LZ-Sub.